提出问题
目前大多数的基于ResNet的网络存在两个问题:
- ResNet网络最初设计是被用来做图像分类的,因此不适合直接拿来做别的任务,如分割和检测
- 缺少通道间的信息交互,虽然已经有一些网络做了弥补(SENet),但是还是存在第一个问题
两个贡献
基于上面的问题,文章作出了两个方面的改进:
- 在原来的ResNet网络结构基础上作出调整,在每一个block中增加了特征图的“split attention”,形成一个独立的模块称为“Split-Attention”模块,网络称为ResNeSt。该网络相比于ResNet其他的变形,计算量没有增加,可以直接作为其他视觉任务的backbone。
- 在图像分类任务中可以使用更大的图像尺寸,同时可以很好的迁移到其他任务中。
介绍网络
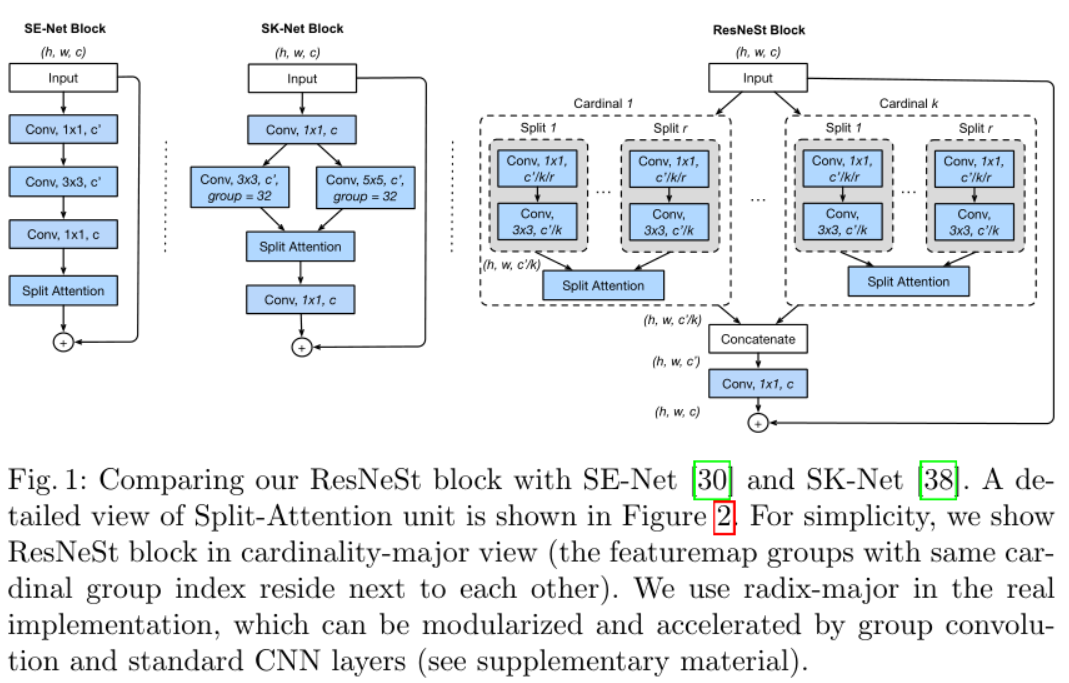
上图最右边就是”Split-Attention block”,但从结构上来看,将虚线框看作一个子模块,该结构就是ResNeXt网络的结构。
Feature-map Group
除了ResNeXt中的超参数$K$之外,该模块还引入了另一个超参数$R$,表示在一个基本组内的划分数(the number of splits),因此,总共的特征组数是$G=KR$。每组表示为$U_i=F_i(X),i \in {1,2,…,G}$。
Split Attention in Cardinal Groups
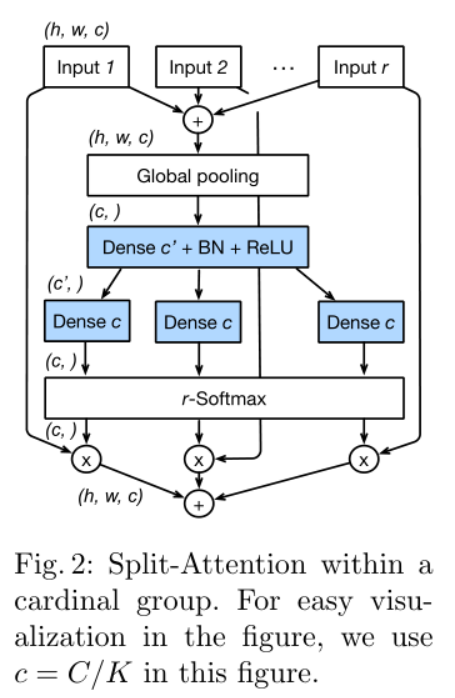
上图是ResNeSt block中的Split-Attention子模块。第$K$个Cardinal Groups表示为$\hat U^K=\sum_{j=R(k-1)+1}^{Rk}U_j$,也就是每一个Cardinal Groups的输出是该组内每一个划分输出之和。文章中公式$s^k_c=\frac{1}{HW}\sum_{i=i}^H\sum_{j=1}^W\hat U_c^k(i,j)$其实表示的是全局平局池化操作,文章中说通过全局平均池化将全局信息和通道信息结合起来。最终的输出$V_c^k=\sum_{i=1}^R\alpha_i^k(c)U_{R(k-1)+i}$是一个加权融合,其中权重$\alpha_i^k(c)$由soft attention得到。这一部分操作较多,比较复杂,建议结合文章和代码理解具体操作。
ResNeSt Block
上一步得到一个Cardinal Group的输出$V^k$,将所有K个输出拼接起来$V=Concat(V^1,V^2…,V^k)$,那么block的最终输出$Y=V+X$,如果在这个过程中特征图大小发生了变化,那么$Y=V+T(X)$,与kaiming he的ResNet操作一致。
训练策略
-
Large Mini-batch Distributed Training
-
Label Smoothing
-
Auto Augmentation
-
Mixup Training
- 当给两个训练图像$(x^i,y^i),(x^j,y^j)$,那么得到的训练数据是
-
Large Crop Size
-
Regularization
- 加入DropBlock
- 引入L2正则