如何做多尺度预测
-
图像金字塔
方法就是将图像Resize到不同尺寸后计算特征图
-
卷积金字塔
对一幅图像使用多个不同大小的卷积核
-
anchors金字塔(faster rcnn方法更加有效)
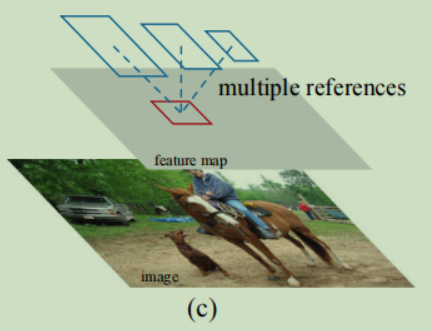
使用不同长宽比和不同尺寸的boxes,(长宽比:(1:2, 1:1, 2:1),尺寸:(8, 16, 32)),共9种anchor boxes
Faster RCNN框架
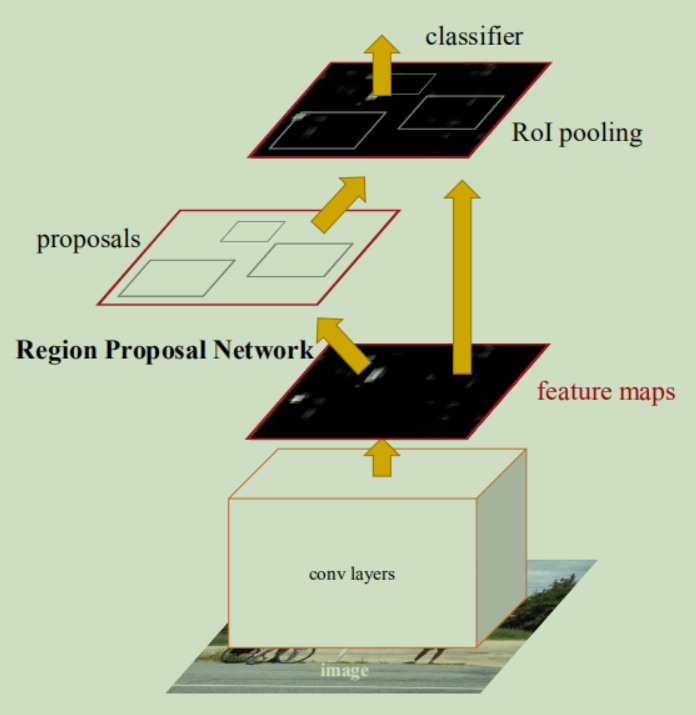
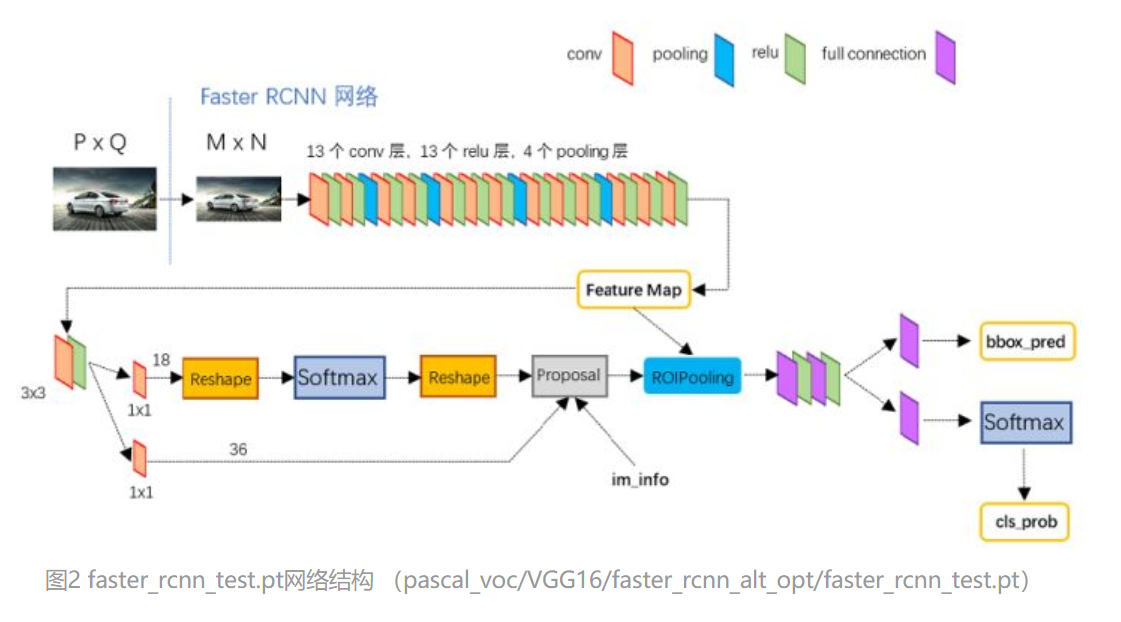 上图是以VGG16为conv layers的细节图,可以看到faster rcnn是由两个网络组成的,一个是RPN(region proposal networks)网络和fast rcnn组成,其中RPN网络的作用相当于fast rcnn的selective search算法,可以生成许多候选框,其次,RPN网络还可以对候选框进行初步的筛选和过滤,可以极大的提高检测速度。此外,由于两个网络共享特征,因此也可以进行端到端的训练。
上图是以VGG16为conv layers的细节图,可以看到faster rcnn是由两个网络组成的,一个是RPN(region proposal networks)网络和fast rcnn组成,其中RPN网络的作用相当于fast rcnn的selective search算法,可以生成许多候选框,其次,RPN网络还可以对候选框进行初步的筛选和过滤,可以极大的提高检测速度。此外,由于两个网络共享特征,因此也可以进行端到端的训练。
接下来就结合上面的网络结构图来具体讲解一下实现过程。
根据论文的实现细节,图像的大小需要re-scale,较短的一边需要rescale到600 pixels,同时,输出步长是16。我们以图像大小为600*900为例,共享卷积层输出的特征图大小就是37*50。
RPN网络
RPN网络的任务就是初步提供检测边框,它的工作流程是这样的:
-
在conv layers后接一个n*n的滑窗(n=3,文中),然后映射到低维特征(对于VGG,就是512维,图上的256是针对ZF网络),接下来特征送进两个全连接层(文中写的全连接,实际上根本不是全连接层,而是全卷积),一个用来做box-regression,另一个做box-classification。
-
针对box-classification这一支路,特征首先经过一个1*1的卷积,输出特征为18(2*9,其中2表示2分类,需要区分出前景和背景,就是有没有目标,9表示特征图上的一个像素点对应9个box,3种长宽比,3种尺寸),得到特征图大小为(c,18,w,h),经过reshape后变成(c,2,w*9,h),经过softmax层,最后再reshape成(c,9,w,h)。
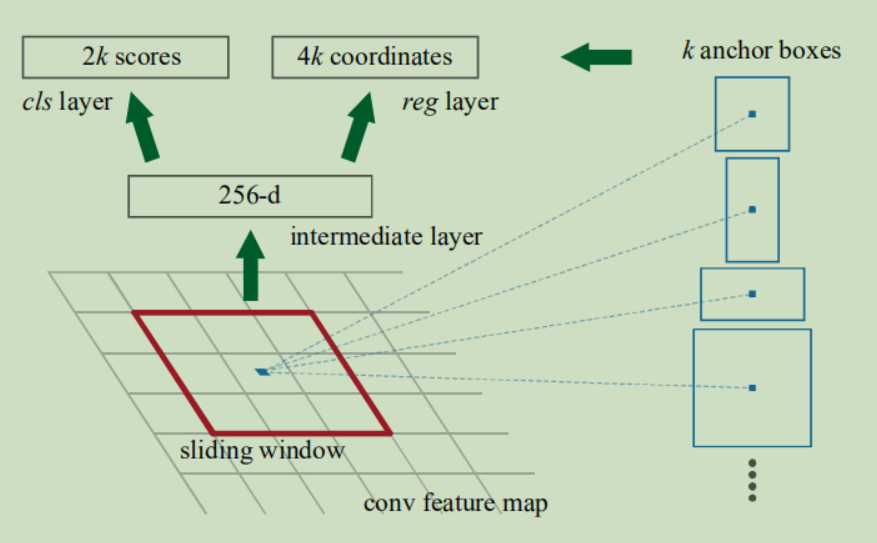
这里需要根据这幅图解释一下9个anchors怎么来的,conv layers的输出大小为(512, 37, 50),然后根据每个像素3*3邻域对应9个anchors,所以一共有37*50*9=16650个box,这些box如何对应到原图上呢?
首先,这9个anchors的大小都是固定的,都是base_anchor(0,0,15,15)这个box经过不同的长宽比和scale得到的,因此这9个anchors的中心点都是(7.5, 7.5),然后将原图(600, 900)划分为(37, 50)的小格子,既就是每边平均分16分,每个格子都是16x16。然后将9个anchors在每个格子上平移,具体见proposal_layer.py的93行。
-
针对box-regression,特征图首先经过一个1*1的卷积,输出特征为36(4*9,4表示每个box需要预测4个量,分别是c_x, c_y, w, h),最后的输出大小是(c, 36, w, h)。
-
这两个支路的输出汇聚到proposal层,这一层所做的事情比较多:
- 首先是将预测的tx, ty, tw, th根据anchors转成box;
- 将越界的box进行clip;
- 在进行nms之前做一次过滤,将box按照有无目标得分排序后,选取pre_nms_topN(12000)个;
- 使用nms过滤;
- 选择前post_nms_topN(2000)个;
- 得到筛选过的大约2000个boxes
-
训练RPN网络:
-
训练box_classification,首先要获得训练标签,就是哪些box是有目标,哪些没有目标,哪些是忽略的。论文里给出了两个定义正样本的准则:
- 将于gt的IOU最大的anchor定义为正样本;
- 将于任何一个gt的IOU大于0.7的anchor都定义为正样本;(准则1是为了防止极端情况)
- 将于所有gt的IOU都小于0.3的anchor定义为负样本,标签为0;
- IOU介于0.3~0.7的anchors忽略;
- 正负样本各取128个,如果正样本不够,就用负样本补充
有了标签后使用交叉熵损失优化。
-
训练box_regression,如何确定回归标签?
已知预测结果是loss中的,是由anchors和gt根据Box Regression计算公式得到的,也就是说,RPN做Box Regression时,所有的box都计算在内。具体见anchor_target_layer.py
-
ROI Pooling层
Faster RCNN最终的输出是预测的box以及类别,就是判断边框围起来的区域的目标类别,以及边框回归,是经过全连接层的,因此需要输入的大小是固定的,而ROI Pooling层就是解决固定输入的问题。
这部分可参考详解ROI Align的基本原理和实现细节,写的很详细。
loss
Faster RCNN的损失由两部分组成,第一部分是RPN的损失,第二部分是RCNN的损失,最终是优化这两部分的总的损失,损失计算见下式:
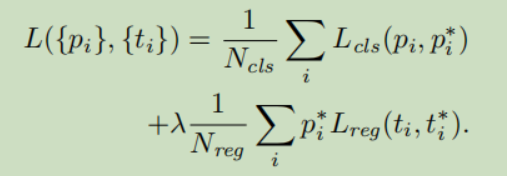
式中,是交叉熵损失,是Smooth_l1损失,针对RPN网络,表示anchor i是目标的概率,,针对RCNN网络,则表示目标属于不同类别的概率;是一个4维向量分别表示(tx, ty, tw, th),表示只对正样本做回归预测。这两项通过和来保持平衡,。
Box Regression计算
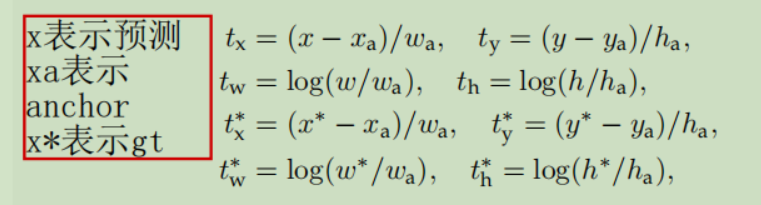
tx是预测的变化量,实际的box大小是x等。
关于数据处理部分
参考
[1] 一文读懂Faster RCNN
[3] pytorch1.0 实现