以下内容是翻译自papersapce上的Pytorch教程系列,目的是为了自己学习时候记录进度督促自己,另一方面也可供需要的人汲取。
PyTorch 101 第四部分:深入了解Pytorch
这是PyToch教程系列第四部分,本次将会介绍使用多卡。
在这部分,我们将学习:
- 如何使用多块GPU来训练网络,使用data parallelism或model parallelism。
- 如何在创建新对象时自动选择GPU。
- 当出现内存问题时如何分析。
开始之前,请记住这是PyTorch系列的第四篇。
可以在这里获取所有代码。
在CPU和GPU上转移Tensor
PyTorch中的每个Tensor都有to()属性,它的任务就是将tensor放在需要调用的设备上,cpu或是gpu,to方法的输入是torch.device对象,它可以被初始化为:
- cpu
- cuda:0,将tensor放在编号0的gpu上
通常,无论何时初始化一个tensor,它都会被放在cpu上,然后可以把它放在GPU上。可以通过torch.cuda.is_available函数来查看GPU是否可用。

也可以通过给to函数传入编号来将tensor放在指定的gpu上。
更重要的是上面的这一小段代码与设备无关,即无需为了在gpu和cpu上工作而单独更改。
cuda()函数
另一个将tensor放在gpu的方法是调用cuda(n)函数,n是gpu的编号,如果只调用了cuda(),tensor将被放在gpu 0上。
torch.nn.Module类同样也有to和cuda函数,可以将整个网络放在特定的设备上,不同的是nn.Module对象也可以调用to方法,而且不需要分配返回的值。(意思就是如果把整个网络放在了gpu上,那么网络计算的输出结果也就自然在gpu上)

自动选择GPU
虽然我们能够清楚知道哪个tensor在哪个gpu上这是很好的,但是通常在操作中我们会创建许多tensor。我们希望这些tensor能自动的被放在特定的设备上,这样可以减少tensor在设备上的迁移,这会拖延代码速度。在这一方面,PyTorch提供了许多功能来完成这些。
首先是torch.get_device函数,它仅支持gpu张量,它返回这个tensor所在的gpu编号。我们可以使用这个函数来决定tensor的设备,因此我们可以自动的将创建的tensor放在设备上。
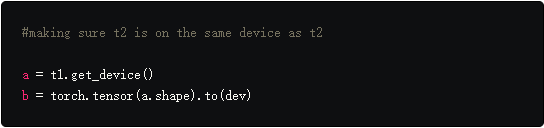
我们同样可以调用cuda(n)当创建新tensor时,这个方法创建的tensor默认都放在gpu 0上,但是可以通过下面的语句更改。

如果由于在同一设备上的两个操作数之间的操作而创建张量,则结果张量也在该设备上,但是如果是位于两个不同的设备操作,则会导致错误。
new_*函数
我们同样可以用PyTorch 1.0中的new_函数。当在Tensor上调用类似new_ones的函数时,它返回一个新的数据类型相同的张量,并且在与调用new_ones函数张量相同的设备上。

其他的new_函数系列可以在PyTorch文档中找到。
使用多GPU
我们有两种方式去使用多GPU:
- Data Parallelism,把一个batch的数据分成更小的部分,然后在多GPU上并行的处理这些小的batch。
- Model Parallelism,将完整的网络分成更小的子网络,然后在不同的GPU上执行这些子网络。
Data Parallelism
在PyTorch中通过nn.DataParallel实现数据并行,通过表示网络的nn.Module对象和GPU编号列表来初始化一个nn.DataParallel对象,这样喂进网络的数据就会被并行化。

接下来就可以想执行nn.Module一样执行nn.DataParallel对象。
1
2
3
4
predictions = parallel_net(inputs) # Forward pass on multi-GPUs
loss = loss_function(predictions, labels) # Compute loss function
loss.mean().backward() # Average GPU-losses + backward pass
optimizer.step()
还有一件事需要说明,尽管数据已经在多GPU上并行化了,但是首先还是需要把它存在单块GPU上。
我们同样需要确保nn.DataParallel对象在指定的GPU上,语法与我们之前使用nn.Module所做的类似。

下面的图描述了nn.DataParallel对象如何工作的。
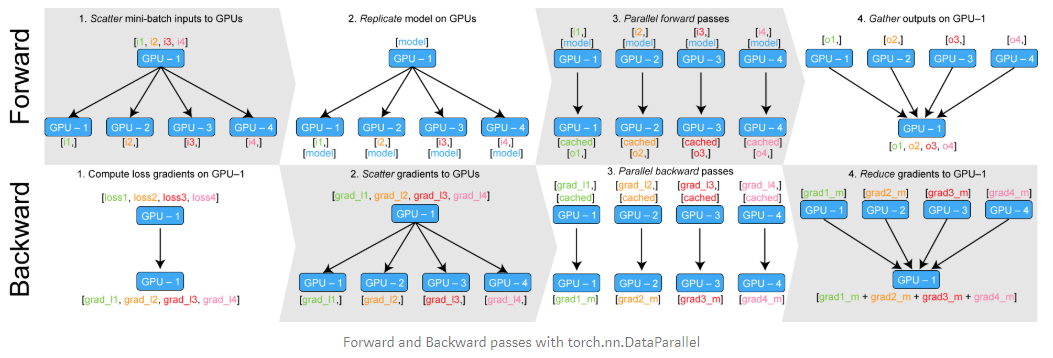
nn.DataParallel对象将送进的数据分成更小的batch,在所有的设备上复制网络,执行然后将
输出收集到原始GPU上。
DataParallel的一个问题是它可以在一个GPU(主节点)上放置非对称负载(就是虽然并行,但是初始的GPU负载更大)。通常有两种方法来规避这些问题:
- 计算前向传播期间的损失,这确保至少在损失计算阶段是并行的。
- 另一个方法就是实现一个并行损失函数层,这超出了本文的范畴,但是如果感兴趣可以参考medium上的这篇实现。
Model Parallelism
模型并行意味着将网络拆成更小的子网络然后放在不同的GPU上,这样做的原因可能就是网络太大而无法容纳在单个GPU中。
模型并行通常比数据并行慢一点,因为将单个网络拆分为多个GPU会在GPU之间引入依赖关系,这会阻止它们以真正的并行方式运行。模型并行的优势不是更快的速度,而是可以运行无法在单个GPU上运行的巨大网络。
在下图中,前向传播期间子网路2需要等子网路1,而反向传播则相反。
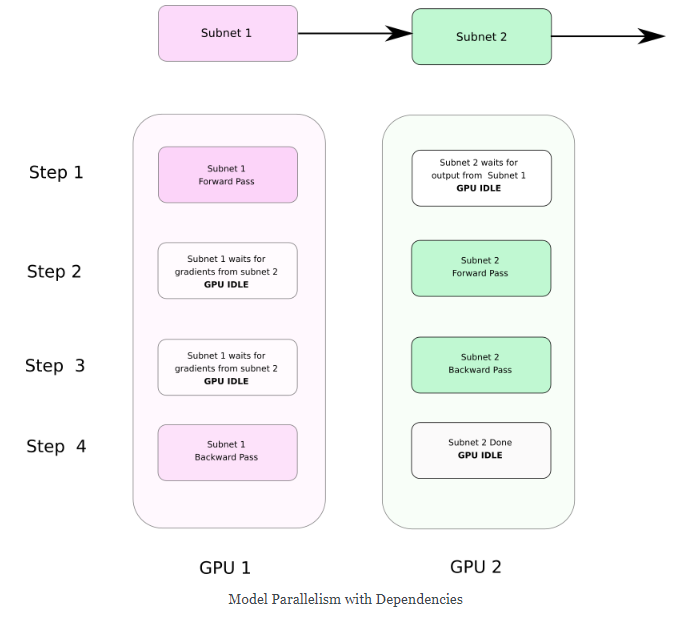
实现模型并行也很简单,只要记住两件事:
- 输入和网络要一直在相同设备上。
- to和cuda函数支持自动求导,因此在反向传播期间梯度可以可以从一块GPU上复制到另一块。
下面的代码帮助你更好的理解。
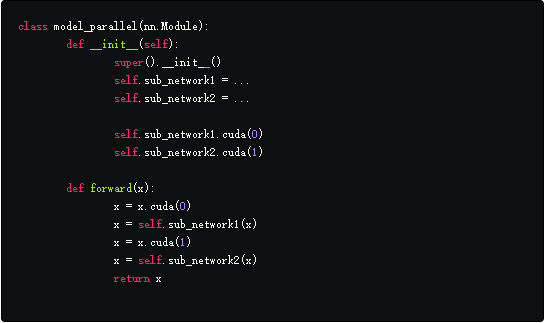
在init函数中,我们已经把子网络分别放在了GPU 0和1上。
注意在forward函数中,我们把中间输出子网络1的输出在送进网络2前迁移到1卡。由于cuda支持自动求导,反向传播的子网络2的损失会被复制到子网络1的缓冲区进一步反传。
Troubleshooting Out of Memory Errors
在本节中,我们将介绍如果您的网络使用的内存超出了所需的内存,如何诊断内存问题和可能的解决方案。
虽然内存不足可能需要减少批量大小,但可以进行一定的检查以确保内存的使用是最佳的。
使用GPUtil跟踪内存使用情况
可以通过在终端使用nvidim-smi命令检测内存使用,但是这种问题在于只能监视内存峰值使用,内存溢出发生很快以至于定位是代码的那部分造成内存溢出。
因此我们使用GPUtil,可以执行下面的语句安装。

使用方法也很简单

只需要把第二行代码放在任何想看GPU使用情况的地方。通过把这句话放在代码的不同地方,你可以准确的找到造成网络内存溢出的地方。
现在让我们谈谈纠正内存溢出错误的可能方法。
使用del关键字处理内存损失
PyTorch有一个非常积极的垃圾收集机制,一旦变量超出范围就会被释放。
需要记住的是,Python并没有像其他语言(如C / C ++)那样强制执行范围规则。只有在没有任何指针指向它的时候,变量才会被释放(这与变量不需要在Python中声明有关)
因此,即使不在训练的循环里,依然无法释放输入张量和输出张量所占用的内存。

运行上面的代码将会输出i的值,即使是在循环里面初始化而在循环外面输出。类似的,张量可以在循环外保存损失和输出,为了真正的释放这些变量,我们使用del关键字。

实际上,如果用完了一个张量,你应该手动del它,因为除非没有任何指针指向它,否则不会被当成垃圾回收。
使用Python数据类型代替一维张量
通常,我们在训练循环中聚合值来计算一些指标。最常见的是我们每次迭代都会更新running loss,然而,如果不注意的话,这可能会使用一些不需要的内存。
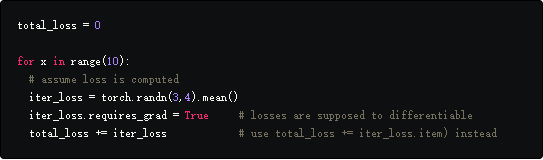
我们希望在后续的迭代中,对iter_loss的引用被重新分配给新的iter_loss,前面表示iter_loss的对象可以被释放。但是不能这样做,为什么?
因为iter_loss是可微的,total_loss += iter_loss这一行通过一个AddBackward函数创建了一个新的计算图。在后续的迭代中,AddBackward节点被加进这个图中,并且不会释放保存iter_loss值的对象。通常,分配给计算图的内存在调用backward时被释放,但是这里没有backwad范围。
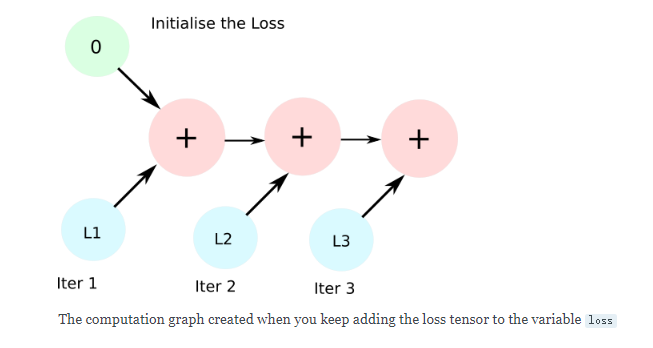
解决的方法就是加一个python数据类型而不是张量,这样会组织创建计算图。
我们只需要将total_loss += iter_loss替换成total_loss += iter_loss.item(),item返回一个只包含值的python数据类型。
清空Cuda缓存
尽管PyTorch可以很轻松的释放内存,但是不会在del张量后把内存返还给操作系统。这片内存被缓存起来方便可以快速的分配给新的张量,而不需要向操作系统申请额外内存。
如果工作流中有超过两个进程,这可能会成为一个问题。
第一个进程会持续占用内存即使工作已经完成,当第二个进程开始时会造成内存溢出。为了解决这个问题,可以在代码末尾加上这句话。

这可以确保该进程所占用的内存被释放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import torch
from GPUtil import showUtilization as gpu_usage
print("Initial GPU Usage")
gpu_usage()
tensorList = []
for x in range(10):
tensorList.append(torch.randn(10000000,10).cuda())
# reduce the size of tensor if you are getting OOM
print("GPU Usage after allcoating a bunch of Tensors")
gpu_usage()
del tensorList
print("GPU Usage after deleting the Tensors")
gpu_usage()
print("GPU Usage after emptying the cache")
torch.cuda.empty_cache()
gpu_usage()
下面是在Tesla K80上执行的结果。

使用torch.no_grad()推断
PyTorch默认在前向传播时会创建计算图,创建计算图时,会分配缓冲区来存储梯度和中间值以便在反向传播时计算梯度。在反向传播时,除了叶子节点,其余变量分配的缓冲区都被释放。
然而,在推断时不需要反向传播,也没有被释放的缓冲区,导致堆积内存。因此,当你要执行一段不需要反向传播的代码时,把它放在torch.no_grad()上下文管理器里。

使用CuDNN后端
可以使用cudnn后端代替vanilla,CuDNN提供了很多可以降低空间利用的优化,尤其是当你的网络输入是固定大小。在代码首行加入下面的来激活CuDNN后端。

使用16-bit浮点数
Nvidia新一代的RTX和Volta卡支持16-bit的训练和推断。

然而,16-bit训练需要采取一些方法。
虽然使用16位张量可以将GPU使用率降低近一半,但它们存在一些问题。
- 在PyTorch中,当使用16-bit浮点时,batch-norm层收敛会出现问题,因此确保batch-norm层是float32。

同样,你需要确保在前向传播时,batch-norm层的输入需要从float16转到float32,然后 输出再转回float16。
这里有更多关于16-bit训练的建议。
- 16-bit浮点数也可能存在内存溢出。因此,请确保对要保存为float16的值具有实际限制。
Nvidia最近发布了一个名为Apex的PyTorch扩展,它有助于在PyTorch中进行数字安全的混合精确训练。链接
结论
这篇文章讨论在PyTorch中使用多卡训练时的一些内存问题。