主要工作
设计了两个模块:HDC和DUC,使得卷积操作更好的应用到图像语义分割中。值得一提的是HDC非常容易在网络中实现,而DUC据说有出奇好的效果(并未尝试)。
Dense Upsampling Convolution(DUC)
DUC模块主要解决的特征解码的问题,也就是图像经过特征提取网络之后如何逐像素预测。目前普遍的方法就是插值上采样+卷积(绝大多数网络的方法)以及反卷积(这个叫法可能不对,但是顺口)这两种方法。它们存在的问题就是1)插值上采样是不可学习的。2)反卷积就是在边缘大量填充0。DUC则是完完全全的纯卷积方法,接下来我们看一下DUC是如何操作的。
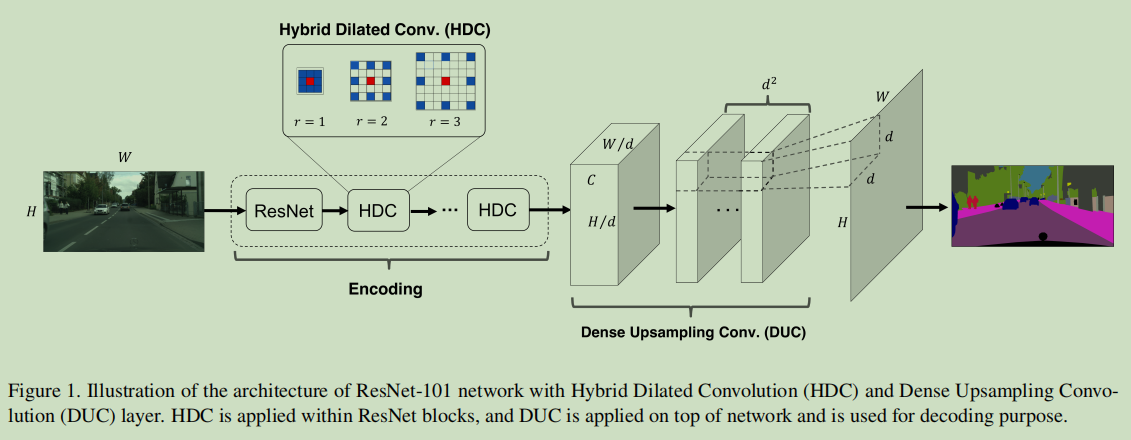
我们有一副图像的大小是$H\times W$,经过特征提取以后维度变成了$h\times w\times c$,其中$h=H/d, w=W/d$,$d$是下采样因子。DUC的做法是通过卷积得到维度为$h\times w\times (d^2 \times L)$,其中$L$是分割任务总的类别数,接下来经过Reshape和Softmax操作得到维度为$H\times W\times L$的分割结果。

至于其中参数的设计可以参考源码中的设计。
Hybrid Dilated Convolution(HDC)
带孔卷积是一种非常好的扩大感受野的方式,然而有一个问题”gridding”,Effective Use of Dilated Convolutions for Segmenting Small Object Instances in Remote Sensing Imagery文章也研究了这个问题。
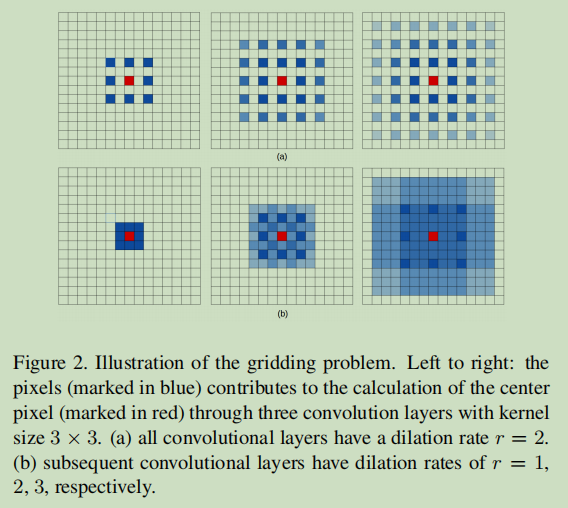
如上图所示,第一行表示扩张率$r=2$是一个固定值,即在每一层都一样,从左到右可以表示连续三层感知域的变化情况,其中蓝色方格表示对中心红色有贡献的区域,可以看到虽然带孔卷积可以扩大感知域,但是实际上参与计算的元素很少,损失了大量信息,这个体现在1)损失了局部信息,2)一些不相干的信息可能因此聚集。
HDC的方法是使用一组扩张率$[r_1, r_2, r_3…r_n]$,HDC的目的是最后的感知域可以完全覆盖整个区域而没有孔洞和失去边缘。因此定义了一个”两个非0值间的最大距离”,其中$M_n=r_n$。具体细节参见文章。
上图第二行,卷积率$r=[1,2,3]$,这样的设计消除了中间空洞的信息损失。HDC的设计指出,许多卷积层以组的形式划分,一组卷积中卷积率的设计遵循“锯齿波”原则,就是卷积率呈扩大趋势,在下一组又重复。同时强调了一组卷积率不要有公因数像[2,4,8]这样的,否则问题依然存在,这是与ASPP的不同点。
应用
HDC可以直接设计在特征提取网络中,而DUC则直接接在编码器之后做上采样。
参考
[1] Understanding Convolution for Semantic Segmentation
[2] 源码