以下内容是翻译自papersapce上的Pytorch教程系列,目的是为了自己学习时候记录进度督促自己,另一方面也可供需要的人汲取。
PyTorch 101 第二部分:搭建自己的神经网络
在这篇文章里,我们将如何使用pytorch来搭建自定义的神经网络以及如何配置训练过程,我们将会实现一个ResNet在CIFAR-10上做图像分类。在开始之前需要说明的是,这篇文章不是为了实现最好的分类精度,而是教你如何使用pytorch。
友情提示:这是我们的PyTorch系列教程的第二部分,我们强烈推荐阅读第一部分,尽管并不是必须去阅读。
可以在这里获得所有的代码。
接下来我们将学习:
- 如何使用nn.Module类搭建神经网络。
- 如何使用Dataset和Dataloader来定制数据输入以及数据增强。
- 如何使用不同的学习率策略调整学习率。
- 在CIFAR-10上训练一个基础的ResNet图像分类器。
预备知识
- 链式法则
- 深度学习基础
- PyTorch 1.0
- 第一部分知识
一个简单的神经网路
接下来,我们会实现一个非常简单的神经网络。
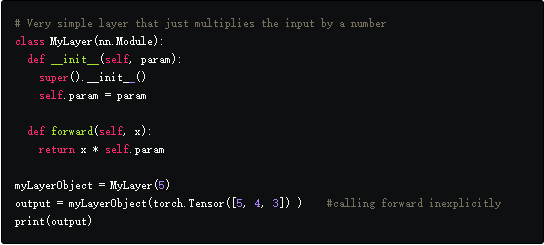
搭建神经网络
torch.nn模块是pytorch中设计神经网络的基础,这个模块可以用来实现全连接层,卷积层,池化层激活函数以及通过实例化torch.nn.Module实现整个神经网络。
许多nn.Module类可以被串联起来形成一个更大的nn.Module类,这就是我们如何实现多层神经网络。实际上,在PyTorch中,nn.Module可以被用来表示任意的函数f。
nn.Module中有两个方法必须重写:
- __init__函数。这个函数在创建一个nn.Module实例时被调用,在这里需要定义不同的变量例如卷积层中的filters, kernel_size,dropout层的dropout probability。
- forward函数。这是定义计算输出的地方,这个函数不需要明确的调用,可以通过调用nn.Module实例来运行,就像一个带有输入做为参数的函数一样。
另一个运用广泛并且重要的类就是nn.Sequential类,启动此类时,我们可以按照特定顺序传递nn.Module对象的列表,返回的对象是一个nn.Module对象,当使用输入运行此对象时,它将按顺序运行通过我们传递给它的所有nn.Module对象的输入,其顺序与传递它们的顺序相同。

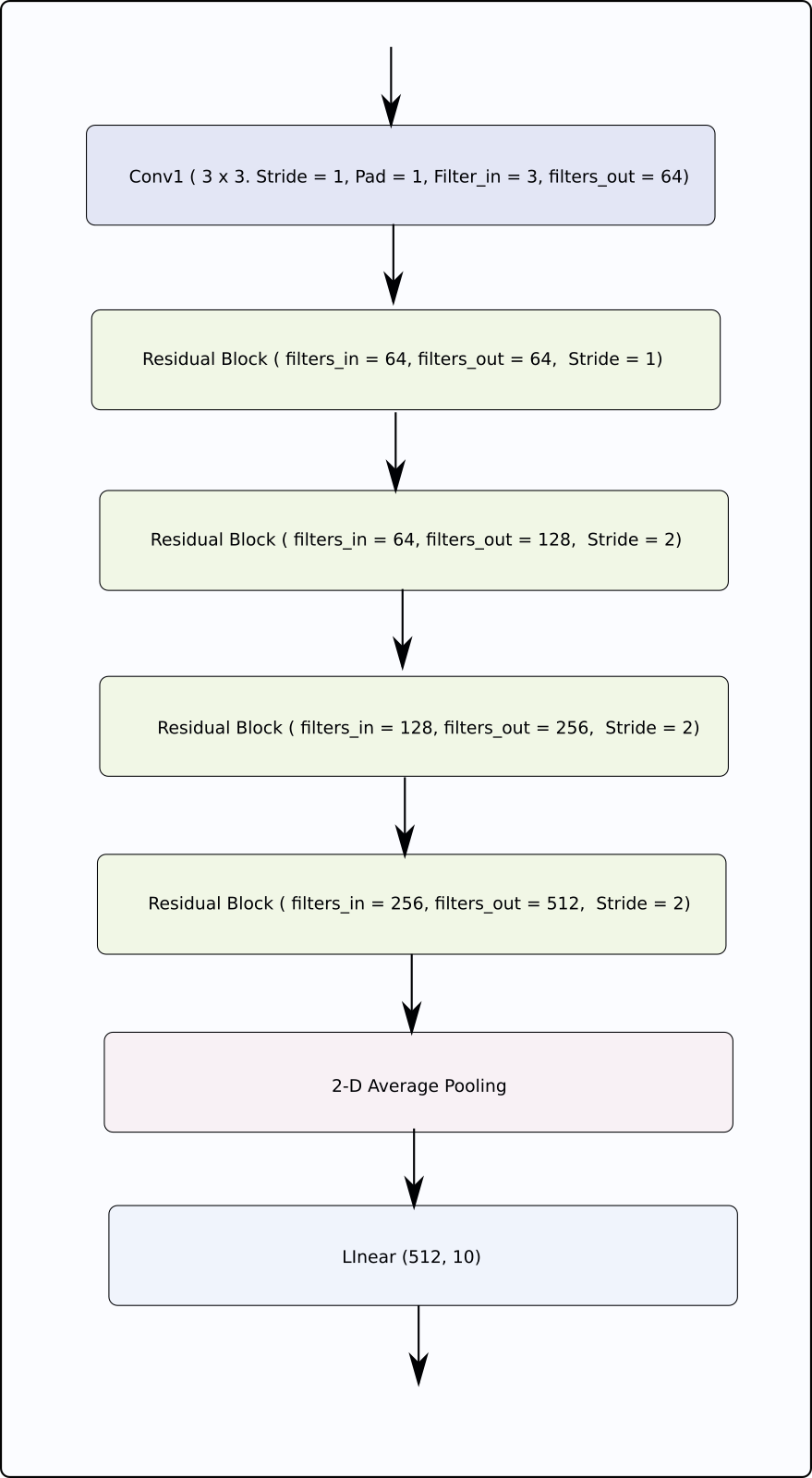
现在让我们开始实现分类网络,我们将利用卷积和池化层以及自定义实现的残差块。
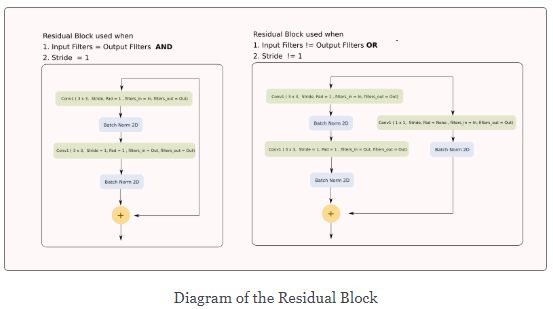
虽然PyTorch提供了许多开箱即用的torch.nn模块,但我们必须自己实现残差块。在实现神经网络之前,我们需要实现残差块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
# Conv Layer 1
self.conv1 = nn.Conv2d(
in_channels=in_channels, out_channels=out_channels,
kernel_size=(3, 3), stride=stride, padding=1, bias=False
)
self.bn1 = nn.BatchNorm2d(out_channels)
# Conv Layer 2
self.conv2 = nn.Conv2d(
in_channels=out_channels, out_channels=out_channels,
kernel_size=(3, 3), stride=1, padding=1, bias=False
)
self.bn2 = nn.BatchNorm2d(out_channels)
# Shortcut connection to downsample residual
# In case the output dimensions of the residual block is not the same
# as it's input, have a convolutional layer downsample the layer
# being bought forward by approporate striding and filters
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(
in_channels=in_channels, out_channels=out_channels,
kernel_size=(1, 1), stride=stride, bias=False
),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = nn.ReLU()(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = nn.ReLU()(out)
return out
如你所见,我们在__init__函数中定义了层或者网络的组件,在forward函数中,我们如何将这些组件串在一起以计算输入的输出。
现在,我们定义整个网络:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
class ResNet(nn.Module):
def __init__(self, num_classes=10):
super(ResNet, self).__init__()
# Initial input conv
self.conv1 = nn.Conv2d(
in_channels=3, out_channels=64, kernel_size=(3, 3),
stride=1, padding=1, bias=False
)
self.bn1 = nn.BatchNorm2d(64)
# Create blocks
self.block1 = self._create_block(64, 64, stride=1)
self.block2 = self._create_block(64, 128, stride=2)
self.block3 = self._create_block(128, 256, stride=2)
self.block4 = self._create_block(256, 512, stride=2)
self.linear = nn.Linear(512, num_classes)
# A block is just two residual blocks for ResNet18
def _create_block(self, in_channels, out_channels, stride):
return nn.Sequential(
ResidualBlock(in_channels, out_channels, stride),
ResidualBlock(out_channels, out_channels, 1)
)
def forward(self, x):
# Output of one layer becomes input to the next
out = nn.ReLU()(self.bn1(self.conv1(x)))
out = self.stage1(out)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = nn.AvgPool2d(4)(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
输入格式
现在我们有了网络,我们将注意力转向输入,在使用深度学习时,我们遇到了不同类型的输入:图像,音频或高维结构数据。
我们正在处理的数据类型将决定我们使用的输入,通常在pytorch中,batch总是第一个维度。由于我们在这里处理图像,我将描述图像所需的输入格式。
输入的图像格式是[B C H W],其中B是batch_size,C是channels,H,W分别是height和width。
由于我们使用了随机权重,我们神经网络的输出现在是乱码。现在让我们训练我们的网络。
加载数据
现在开始加载数据,我们将利用torch.utils.data.Dataset和torch.utils.data.Dataloader类。
我们首先将CIFAR-10数据集下载到当前目录下。启动终端,cd到您的代码目录并运行以下命令。

如果您使用的是macOS,则可能需要使用curl,如果您使用的是Windows,则需要手动下载。
现在我们将读取CIFAR数据集中存在的标签。

我们使用PIL库来读图片,在写加载数据的功能之前,我们先完成预处理函数完成如下:
- 以0.5的概率随机水平翻转图像。
- 用CIFAR数据集的均值和方差归一化数据。
- reshape [W H C]—>[C H W]。
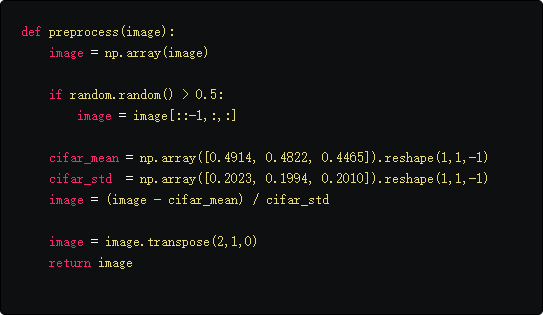
通常,pytorch提供两个类构建输入管道来加载数据。
- torch.data.utils.dataset,我们称其为dataset类。
- torch.data.utils.dataloader,我们称其为dataloader类。
torch.utils.data.dataset
dataset是一个加载数据的类,返回一个可以迭代的生成器,它还允许将数据增强技术合并到输入管道中。
如果你想为自己的数据创建一个dataset类,你需要重载三个函数:
- __init__函数。定义与你自己数据相关的元素,更重要的是,数据的位置,还可以定义想用的数据增强。
- __len__函数。返回数据集的长度。
- _getitem__函数。这个函数输入一个参数index i,返回一个数据样例,在我们的训练循环期间,每次迭代都会调用此函数,数据集对象使用不同的i。
以下是加载CIFAR数据的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class Cifar10Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir, data_size = 0, transforms = None):
files = os.listdir(data_dir)
files = [os.path.join(data_dir,x) for x in files]
if data_size < 0 or data_size > len(files):
assert("Data size should be between 0 to number of files in the dataset")
if data_size == 0:
data_size = len(files)
self.data_size = data_size
self.files = random.sample(files, self.data_size)
self.transforms = transforms
def __len__(self):
return self.data_size
def __getitem__(self, idx):
image_address = self.files[idx]
image = Image.open(image_address)
image = preprocess(image)
label_name = image_address[:-4].split("_")[-1]
label = label_mapping[label_name]
image = image.astype(np.float32)
if self.transforms:
image = self.transforms(image)
return image, label
我们使用__getitem__函数提取每张图片的标签。
Dataset类允许我们合并延迟数据加载原则。这意味着它不是一次性加载所有的数据到内存中,而是当需要时只加载一个数据(__getitem__调用时)。
一旦你创建了一个Dataset类,基本上可以用任何python迭代器的方法来迭代对象,每一次迭代,__getitem__函数以i作为输入参数。
数据增强
在__init__函数中还传入了一个参数transforms,它可以是任何做数据增强的python函数。你也可以在预处理代码中做数据增强,在__getitem__中做只是习惯问题。
这里我们也加入了数据增强,这些数据增强既可以是函数也可以是类实现。你只需要保证可以在__getitem__函数中应用这些来获得期望的输出。
我们有大量的数据扩充库可用于增强数据。例如,torchvision库提供了许多预建的变换,并且能够成更大的变换,但是我们的讨论仅限于pytorch。
torch.utils.data.Dataloader
Dataloader类很方便:
- Batching of Data。
- Shuffling of Data。
- 使用多线程同时加载许多数据。
- 预取。当GPU处理当前批数据时,Dataloader可以同时将下一批处理加载到内存中。这意味着GPU不必等待下一批,它可以加快培训速度。
使用Dataset对象实例化Dataloader对象,然后可以像对数据集实例一样迭代Dataloader对象实例。然而,你可以指定各种选项,以便可以更好地控制循环选项。
1
2
3
4
5
trainset = Cifar10Dataset(data_dir = "cifar/train/", transforms=None)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testset = Cifar10Dataset(data_dir = "cifar/test/", transforms=None)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=True, num_workers=2)
trainset和testset都是python生成器对象,可以通过下面的语句迭代:

Dataloader类加载数据比Dataset更加方便,在每次迭代中,Dataset类仅返回__getitem__函数的输出,Dataloader做的更多:
- 注意trainset的__getitem__方法返回一个形状是$3\times 32\times 32$的矩阵,Dataloader将图像打包成形状是$128\times 3\times 32\times 32$的Tensor。
- 当__getitem__方法返回一个矩阵时,Dataloader类自动转换成一个Tensor。
- 即使__getitem__方法返回一个非数字类型的对象,Dataloader类将它转换成一个size是B的list/tuple。假设__getitem__也返回一个字符串,即标签字符串,如果在实例化Dataloader时设置$batch=128$,每次迭代时,Dataloader将会返回一个128个字符串的元组。
训练和评估
在开始写训练循环之前,需要先决定超参数和优化算法,PyTorch通过torch.optim提供了许多内建的优化算法。
torch.optim
torch.optim模块提供许多优化算法。
- 不同优化算法(optim.SGD,optim.Adam)
- 可以调节学习率(用optim.lr_scheduler)
- 不同的参数有不同的学习率(本节不讨论)
我们将使用cross entropy loss和基于动量的SGD优化算法,学习率在第150轮和200轮以0.1的因子衰减。
1
2
3
4
5
6
7
8
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #Check whether a GPU is present.
clf = ResNet()
clf.to(device) #Put the network on GPU if present
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(clf.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[150, 200], gamma=0.1)
第一行中,如果有GPU,device就是“cuda:0”,否则就是“cpu”。默认情况下,当我们初始化一个网络,它保留在CPU上,clf.to(device)将网络移到GPU上,在后面的系列中将讲述如何使用多块GPUs。我们也可以使用clf.cuda(0)将网络clf移到GPU 0。(0是GPU编号,可替换)
criterion是一个nn.CrossEmtropy类,如名字所示,实现cross entropy loss,也是nn.Module的子类。
接着定义变量optimizer做为一个optim.SGD对象,第一个参数是clf.parameters(),parameters()函数返回nn.Module对象的参数(由nn.Parameters对象实现,将在下一节探索高级PyTorch功能中学习,目前,可以认为是一个与Tensors有关的可学习的列表)。clf.parameters()基本上是神经网络的权重。
正如代码中所示,我们将调用优化器上的step()函数。调用step()时,优化器使用梯度更新规则方程更新clf.parameters()中的每个Tensor,通过调用每个Tensor的grad属性获取梯度。
通常,任何优化器的第一个参数,无论是SGD,Adam或是RMSprop,都是Tensors列表,它支持更新,其余的参数是不同的超参数。
scheduler,顾名思义,可以调节optimizer的超参数。optimizer用来实例化schduler,每次在调用scheduler.step()时更新参数。
写一个训练循环
我们最终训练了200轮,你可以增加轮数,在GPU上将会花费一点时间,本教程的工作重点是展示PyTorch如何工作而不是达到最佳准确度。
我们在每轮评估了分类精度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
for epoch in range(10):
losses = []
scheduler.step()
# Train
start = time.time()
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad() # Zero the gradients
outputs = clf(inputs) # Forward pass
loss = criterion(outputs, targets) # Compute the Loss
loss.backward() # Compute the Gradients
optimizer.step() # Updated the weights
losses.append(loss.item())
end = time.time()
if batch_idx % 100 == 0:
print('Batch Index : %d Loss : %.3f Time : %.3f seconds ' % (batch_idx, np.mean(losses), end - start))
start = time.time()
# Evaluate
clf.eval()
total = 0
correct = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = clf(inputs)
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum()
print('Epoch : %d Test Acc : %.3f' % (epoch, 100.*correct/total))
print('--------------------------------------------------------------')
clf.train()
现在,上面是一大块代码,虽然我在代码中添加了注释以告知读者发生了什么,但我现在将解释代码中不那么重要的部分。
我们首先在每轮开始调用了scheduler.step()来确保optimizer使用正确的学习率。
循环里的第一件事情就是把input和target移到GPU上,和模型在相同的设备上,否则pytorch就会抛出错误并停止。
注意我们在前向传递之前调用optimizer.zero_grad(),这是因为叶子Tensors会保留之前前向传递的梯度,如果在损失上再次调用backward,那么新的梯度就会加在之前的梯度上。这个功能方便RNNs工作,但是现在我们需要将梯度设为0以便梯度不会在后续传递之间积累。
我们将评估代码放在了torch.no_grad管理器中,这样在评估时就不会创建图,如果对此感到困惑,可以参考第一部分自动求导的概念。
同样要注意我们在评估之前调用了clf.eval(),然后是clf.train(),pytorch中的模型有两个状态eval()和train()。它们之间的主要区别在于像BatchNorm这样的状态层和Dropout,它们在训练和推断时表现不一样:eval时进入推断模式,train时进入训练模式。
总结
这是一个详尽的教程,我们向您展示了如何构建基本的分类器,这仅仅是开始,我们已经涵盖了所有的模块可以使你开始用pytorch开发深度网络。
下一节,我们将研究PyTorch中的一些高级功能,这些功能将增强深度学习设计,这些包括创建更复杂架构的方法,如何定制培训,例如为不同参数设置不同的学习率。
传送门
-
更多PyTorch 例子