动机:提出一种可以将真实世界的场景迁移到动漫中的网络
贡献:
- 提出了一个可以映射的网络结构,使用不成对的图像训练,超过目前的水平。
- 提出了一个简单有效的损失函数。
- 使用初始化网络的方法提高训练。
CartoonGAN
网络框架由两个CNNs组成,一个是生成器,另一个是判别器。
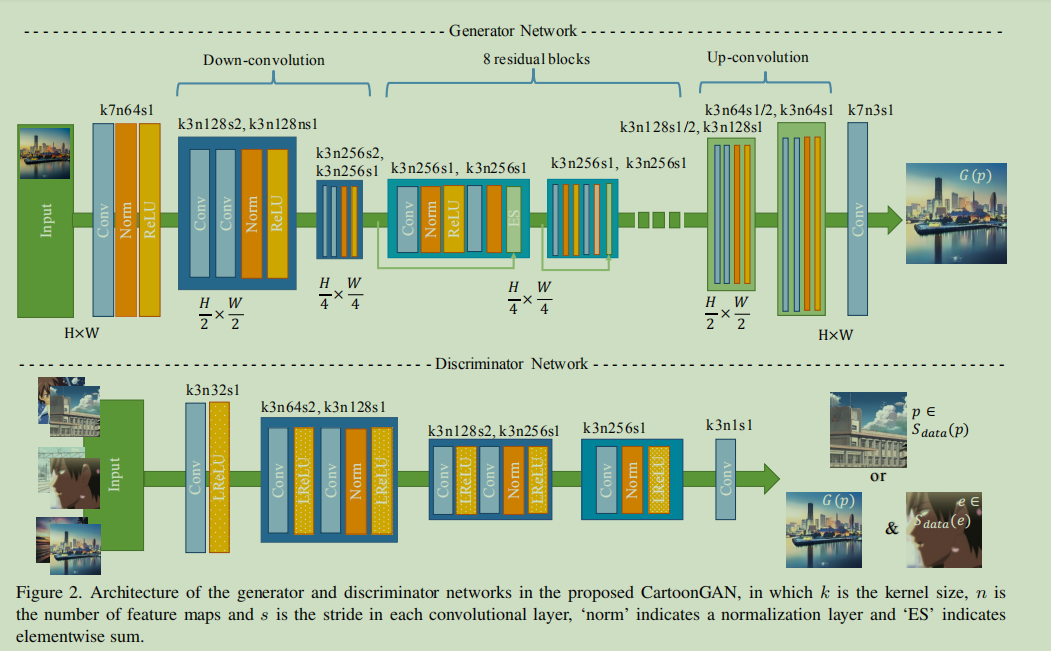
生成器的作用是将一张真实世界的图像映射到卡通图像,生成网络以一个flat convolution开始,后面跟着两个down-convolution来做空间压缩和图像编码,在这个过程中提取了有用的局部信息,最后使用8个残差块来构建内容和主要的特征信息,最后通过up-convolution来重建卡通图像。
判别器主要用来判别图像的来源,用于是一个less demanding task,因此采用了patch-level的判别器(patch-level来源于pix2pix),判别网络比较浅,基本上和一般的判别器一样,激活函数选择了LeakyReLu 。
损失函数
损失函数由两部分组成:
-
adversarial loss,使得生成网络能够将图像从photo域映射到cartoon域。
-
content loss,在映射过程中能够保护图像内容。
因此损失函数就是
w用来平衡两个损失函数,w大使得保留更多的内容信息,但是肯定也会影响映射的效果。在实验中令w=10。
adversarial loss
在实验中发现,卡通图像往往有更加清晰的边缘,但由于边缘的内容太少,因此很难保留,所以生成器就会倾向于生成阴影来欺骗判别网络从而减小损失。为了解决这个问题,从卡通图像中生成了一些边缘模糊的卡通图像。步骤如下:
- 使用Canny边缘检测器检查图像边缘。
- 膨胀边缘区域。
- 对边缘区域使用高斯平滑。
处理完的图像如下所示

最后,定义了一个edge-promoting adversarial loss:
content loss
在CartoonGAN中为了保护内容信息,采用VGG网络中的高层特征信息。
采用l1 loss的原因是卡通图像的特征:清晰的边界和平滑的阴影。采用了”conv4_4”层的特征来计算content loss。
一个重要的trick: Initialization phase
我们知道生成器的任务就是以卡通的风格重建真实图像而保留重要的内容信息。出于这个目的,在预训练阶段,只用content loss来训练生成器。这个trick帮助模型更快的收敛到一个最优结果。预训练结果如图

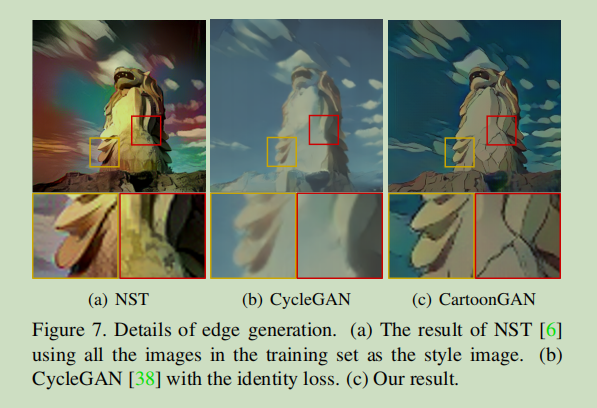
实验结果



参考
[1] pytorch CartoonGAN实现
[2] Tensorflow 实现
[3] 文章链接