动机:
计算资源限制了CNN在移动设备上做dense estimation tasks。
解决方法:设计轻量级网络兼顾分割精度和效率
-
模型压缩方法(network compression):通过压缩预训练模型来减少inference时的计算量,常用的方法有hashing,pruning和quantization以及稀疏编码理论。
-
卷积分离方法(convolution factorization):把一个标准卷积分解成group convolution和depthwise separable convolution,侧重于直接训练较小的网络。
本文方法:
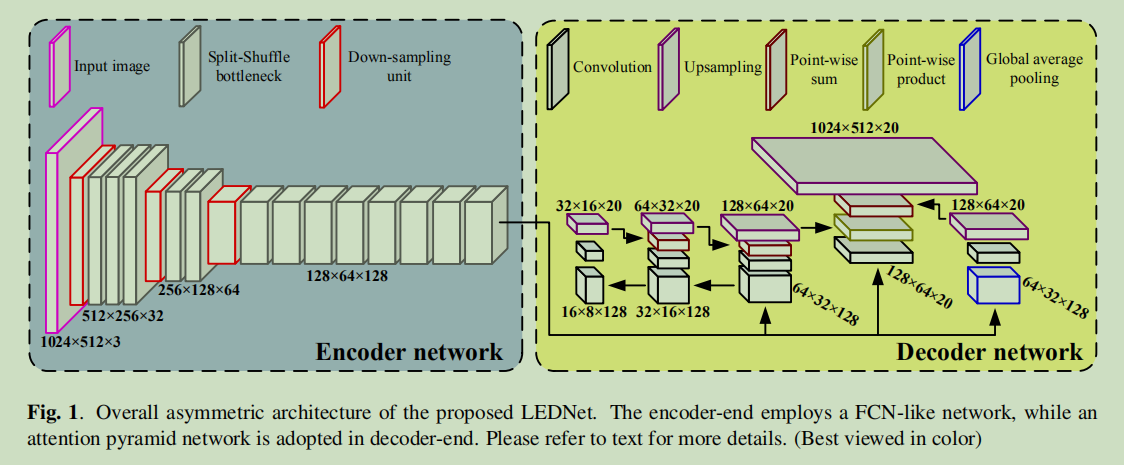
概述:采用一个非对称的encoder-decoder结构,encoder采用ResNet,在每个residual block中加入两个操作:channel split 和 shuffle来减少计算资源的同时保证精度,同时在decoder中引入attention pyramid network(APN)进一步减轻模型复杂性。
优点:少于1M的参数量,单块GTX 1080 Ti 上超过71 FPS。
本文贡献:
-
采用非对称结构,极大减少了网络参数量,加速了推断过程。
-
channel split 和 shuffle 操作可以嵌入模型做end-to-end训练。
-
APN进一步减轻了模型复杂度。
模型参数:
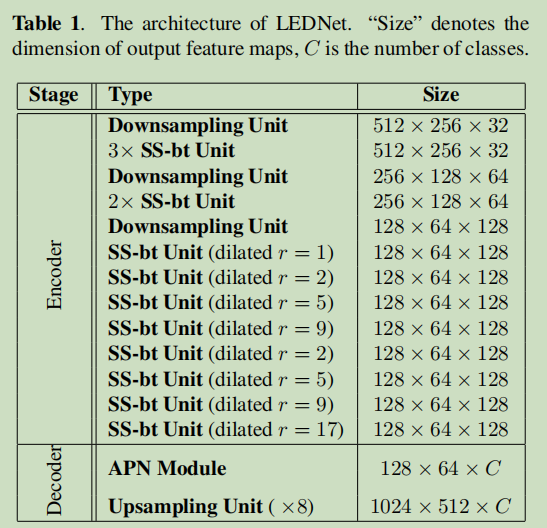
一个细节:文中提到,Besides SS-bt unit, the encoder also includes downsampling unit, which is performed by stacking two parallel output of a single 3x3 convolution with stride 2 and a Max-pooling。也就是说encoder中的Downsampling Unit是两个并行的结构。具体见代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class DownsamplerBlock (nn.Module):
def __init__(self, in_channel, out_channel):
super().__init__()
self.conv = nn.Conv2d(in_channel, out_channel-in_channel, (3, 3), stride=2, padding=1, bias=True)
self.pool = nn.MaxPool2d(2, stride=2)
self.bn = nn.BatchNorm2d(out_channel, eps=1e-3)
self.relu = nn.ReLU(inplace=True)
def forward(self, input):
output = torch.cat([self.conv(input), self.pool(input)], 1)
output = self.bn(output)
output = self.relu(output)
return output
两个模块:
-
SS-bt module:
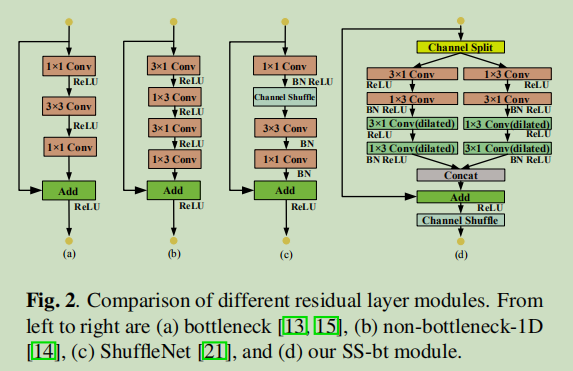
上图最右边就是提出的 split shuffle bottleneck 模块。首先将input分成两个分支,每个分支的channels是input的一半,然后分别对每个分支做卷积操作,将特征图做concat,接着加上input,最后做 channel shuffle操作来促进两个分支的信息沟通。
-
APN :见Fig1右侧decoder中,添加了三个不同尺寸的特征。
-
首先对encoder 的输出a 依次用3x3,5x5,7x7,stride=2的卷积来形成多尺度特征金字塔。
-
然后一步步做信息融合得到b。(decoder左侧)
-
对a用1x1 的卷积获得特征信息c,然后做b与c的point-wisely-product。(中间,注意力机制)
-
为了更好提高性能,加入了全局信息。(右侧)
-
最后上采样到原始分辨率。
-
训练细节:
-
训练数据集:CitySpaces dataset
-
input_size:1024x512x3
-
batch_size:5
-
initial learning rate:0.0005,采用ploy策略
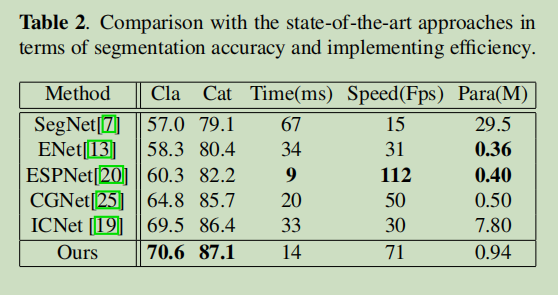
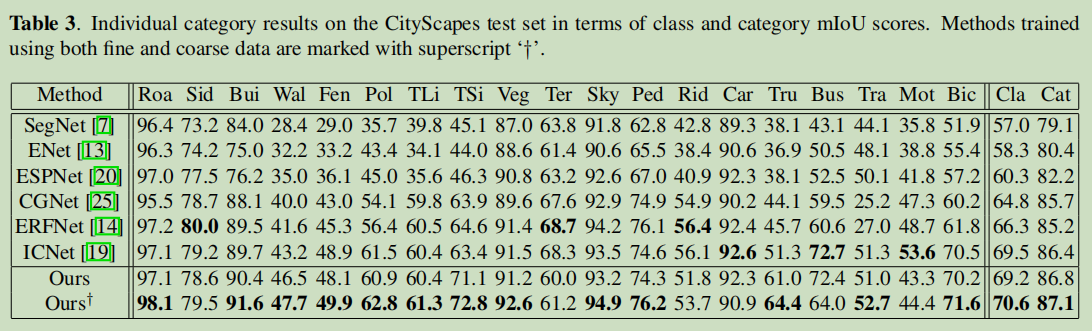
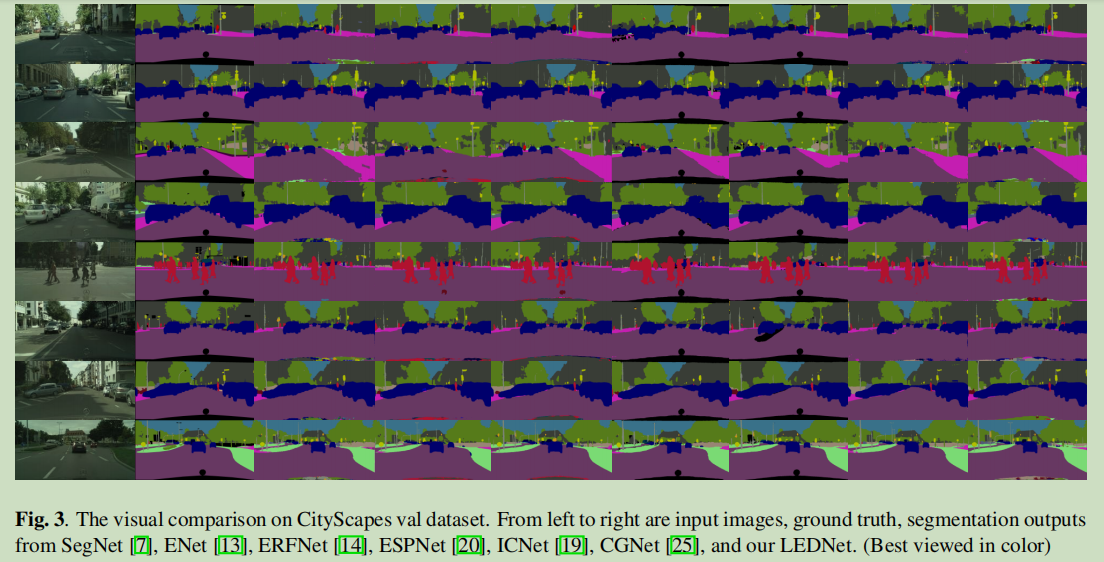
实验结果:
参考:
[1] LEDNET: A LIGHTWEIGHT ENCODER-DECODER NETWORK FOR REAL-TIME SEMANTIC SEGMENTATION
[2] pytorch 实现
[3] keras 实现