动机:
在实际应用中,需要区别一些易混淆的类别,比如field和grass
目前的方法:
1. 利用多尺度信息融合:
- 主要操作:
- combine feature maps generated by different dilated convolution and pool operation。
- enlarge the kernel size with a decomposed structure or introduce an effective encoding layer on the top of the network。
- 存在的问题:尽管信息融合可以获得不同scale的目标,但是不能利用目标间的关系或全局感受野的内容。
2. 利用循环卷积网络来发现long-term dependencies:
- 存在的问题:虽然可以获得全局关系,但是效果严重依赖于long-term memorization 的学习结果。
本文提出的网络:Dual Attention Network
分别在spatial和channel维度引进一个self-attention机制,也就是在传统的FCN顶部加入两个并行的attention模块。
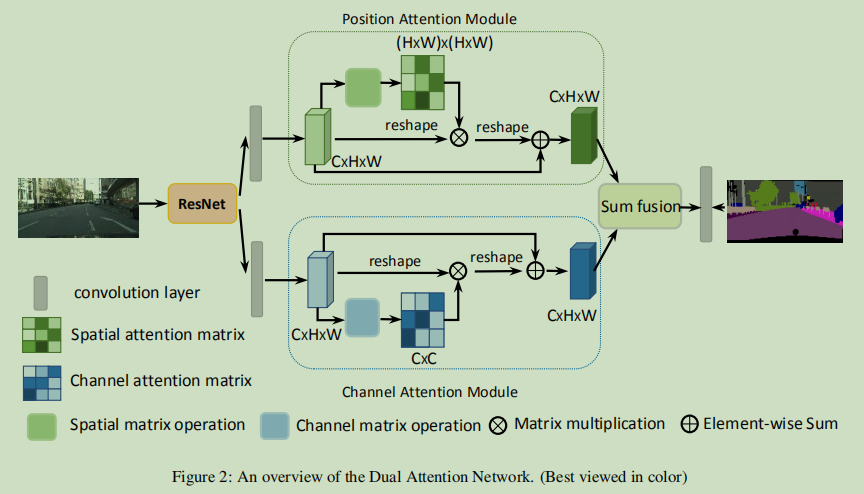
实现细节
- employ a pretrained residual network with the dilated strategy as the backbone
- remove the down-sampling operations and employ dilation convolutions in the last two ResNet blocks, thus enlarge the size of the final feature map size to 1/8 of the input image.
两个模块
-
position attention module: capture the spatial dependencies between any two position of the feature maps.
- 操作细节:For feature at a certain position, it is updated via aggregating features at all positions with weighted summation, where the weights are decided by the feature similarities between the corresponding two positions. That is, any two positions with similar features can contribute mutual improvement regardless of their distance in spatial dimension.
-
channel attention module: capture the channel dependencies between any two channel maps, and update each channel map with a weighted sum of all channel maps.
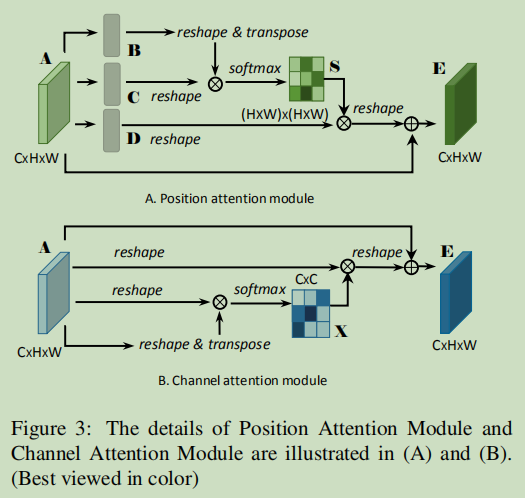
操作流程
-
position attention module: A的维度是CxHxW,经过Conv+BN+Relu后分别得到B,C,D,维度均为 CxHxW,将 B,C,D reshape 到CxN,其中N=HxW,将 B 的转置(NxC)与C相乘,再经过softmax得到S(spatial attention matrix)S的维度是NxN。
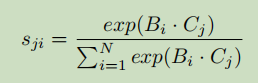
S_ji 表示第i 个位置对第j 个位置的影响。可以看到两个位置上,越是相近的特征贡献越大。接着将S 的转置与 D 做矩阵乘再reshape到CxHxW维度,最后加上特征A得到输出E。
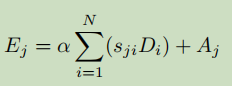
- channel attention module: 与__position attention module__相同,不需要经过卷积层,这样可以保持不同通道之间的关系。
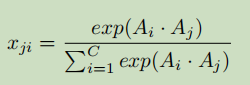
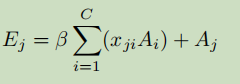
- 最后,输出结果经过Conv+BN+Relu后加在一起,经过一个卷积层得到预测结果。
- pytorch实现:
1
2
3
4
5
6
7
8
9
10
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1)
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)
energy = torch.bmm(proj_query, proj_key)
attention = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
其他细节
- poly learning rate policy, initial learning rate is mutiplited by (1-iter/total iters)^0.9。 initial learning rate=0.01
- batch_size = 8(Cityspaces) or 16。
- 数据增强包括Randomcrop和Flip
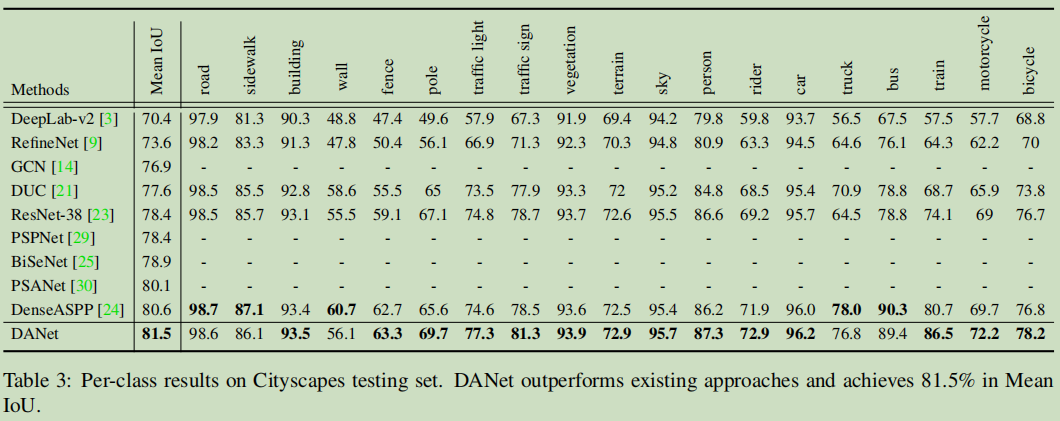
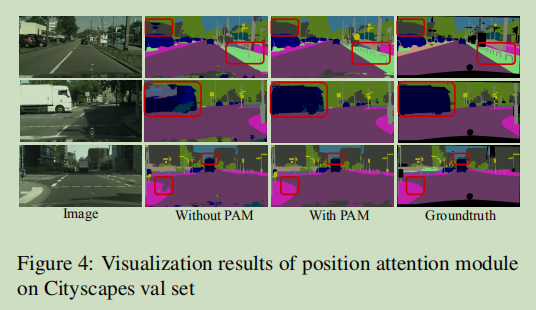
结果
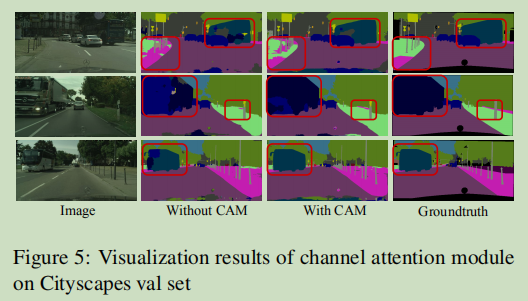
参考
[1] Dual Attention Network for scene segmentation https://arxiv.org/abs/1809.02983
[2] pytorch实现 https://github.com/junfu1115/DANet
[3] torch.bmm() https://pytorch.org/docs/stable/torch.html?highlight=torch%20bmm#torch.bmm